
Capítulo 1 - Explicación

Contexto
La importancia de la habilidad/técnica desarrollada en este módulo trasciende la relevancia de ser sólo una habilidad más en tu repertorio. Aprender a programar y sentirte seguro usando lenguajes de programación como Python, SQL o R te ayudará de forma decisiva en la búsqueda de un empleo ya que es una de las habilidades más demandadas en los profesionales del SIG. Tu interés y proactividad yendo más allá de lo que se requiere en los currículos académicos formales (asignaturas regladas) y la búsqueda continua de información para mejorar tus habilidades de programación es la clave para convertirse en un programador eficiente y en un mejor experto en SIG. Desafortunadamente, este curso solo arañar la superficie de lo que necesitas aprender, pero esperamos que te llegue a convencer de la relevancia y el poder de la programación (visualiza el siguiente video para motivación adicional). La programación puede hacer que tareas redundantes y repetitivas a lo largo del proceso de creación de geoinformación (desde la adquisición de datos hasta divulgación de la información) se conviertan en procesos muy eficientes en las que se puede mejorar de forma extraordinaria la velocidad y precisión de las tareas. Puede también ayudarte en la gestión de grandes conjuntos de datos geoespaciales (Big Data), algo que se está convirtiendo en la norma para los profesionales de los SIG, y asistirte en la resolución de problemas a escalas de trabajo que no puedes imaginar. Esta es la razón por la cual este módulo toma una posición central en la figura anterior y el motivo por el cual no deberías desesperarte si encuentras difícil seguirlo. Respira profundo, mantén una mente abierta y piensa acerca de lo que dominar está (compleja) técnica puede hacer por ti y por tu carrera profesional. .
Lectura de datos
i. Descripción de los datos a manejar
Vamos a practicar la descarga de conjuntos de datos en un Jupiter Notebook con la librería Pandas de un archivo Excel con información acerca de producción de granjas en Europa.
Archivo local: datos/animalEurostatNuts2.xlsx
ii. Lectura de archivos de datos
PARA APRENDER MÁS….
Los formatos de datos soportados por las librerias Pandas y como leerlos se describen en: https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
Format | Read | Write |
csv | pd.read_csv() | pac.to_csv() |
json | pd.read_json() | pac.to_json() |
excel | pd.read_excel() | pac.to_excel() |
hdf | pd.read_hdf() | pac.to_hdf() |
sql | pd.read_sql() | pac.to_sql() |
... | ... | ... |
Cada operación de lectura de un archivo diferente tiene parámetros distintos para ajustar el proceso.
a. Lectura de archivos de Excel
Usamos pandas.read_excel() para leer el archive Excel y alamacenar los datos en un marco de datos (dataframe).
Los parámetros más relevantes son:
io = la dirección (directorio) del archivo
sheet_name = la hoja que se va a leer
PARA APRENDER MÁS….
Hay muchos parámetros para tener en cuenta
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
La carga de la información se puede hacer desde un archivo local o desde una archivo de una web.
Input [1]:
import pandas as pd
import numpy as np
file = 'datos/animalEurostatNuts2.xlsx'
data = pd.read_excel(file, sheet_name='Data', )
print("Done")
Output [1]:
Done
b. Visualización básica de los datos
Podemos visualizar las primeras y últimas filas de la table para comprobar que se han cargado correctamente.
Input [2]:
data.head(10)
Output [2]:

Input [3]:
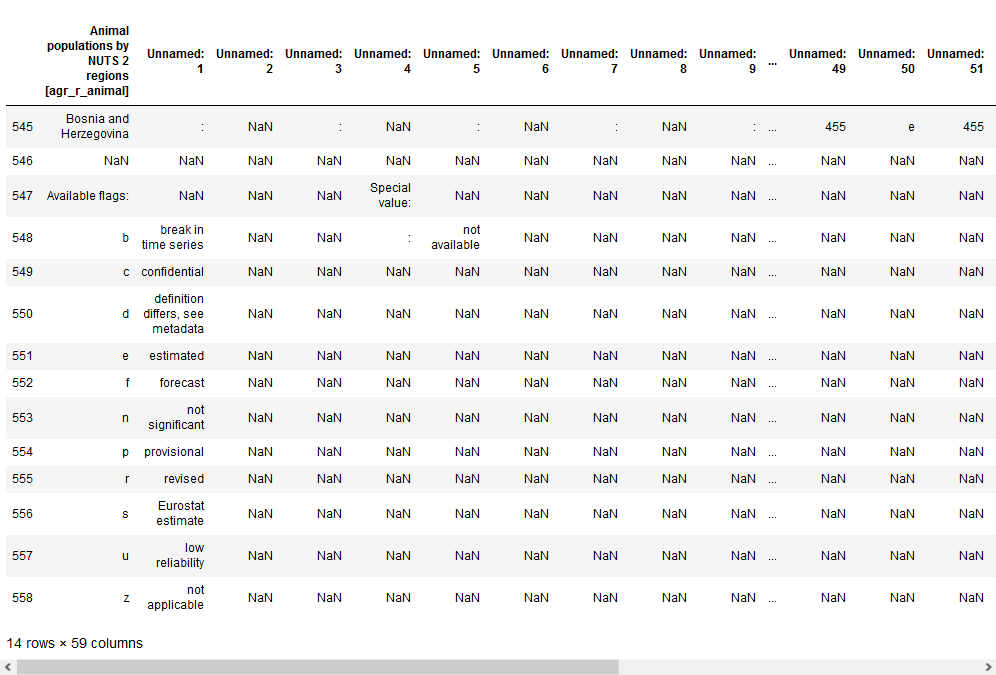
data.tail(14)
c. Ajustes y parámetros de los procesos de carga
Podemos ver que las primeras 9 filas y las últimas 13 no contienen datos válidos, son filas de metadatos de la tabla.
Estas filas deberían ser ignoradas cuando se lee la tabla. La primera fila para leer debe contener los encabezados de la columna.
Además, la primera columna es descriptiva de la información de cada fila.
Input [4]:
data = pd.read_excel(file, sheet_name='Data', skiprows=9, skipfooter=13, index_col=0)
print("Done")
Output [4]:
Done
Input [5]:
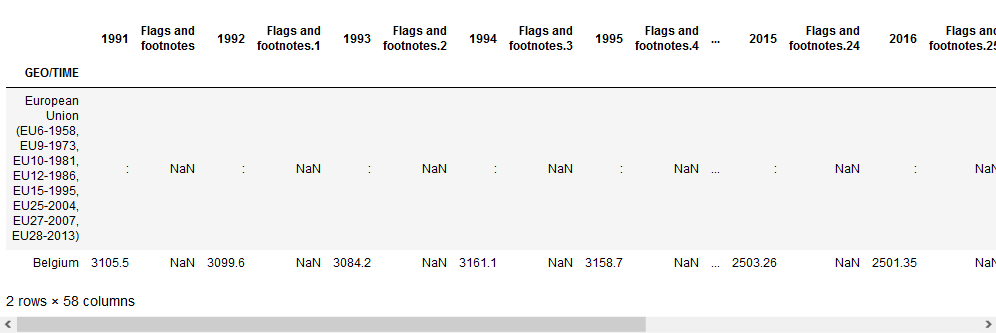
data.head(2)
Output [5]:
Input [6]:
data.tail(3)
Output [6]:

Continua… Módulo 3 – Capítulo 2