
Capítulo 2 - Explicación

Previamente… Módulo 3 - Capítulo 2
Explorando los datos
Una vez los archivos de datos se ha subido, es necesario analizar su contenido para identificar y corregir problemas y errores contenidos.
Visualización de los tipos de datos de las columnas
Es importante mirar a los tipos de datos para identificar si son consistentes con los datos que leemos.
En este caso se ve que los datos son numéricos pero el tipo de dato no identifica los identifica correctamente. Esto implica que valores no numéricos en esta columna tendrán que ser eliminados pues es una columna de datos numéricos.
Input [10]:
data.info()
Output [10]:
<class 'pandas.core.frame.DataFrame'>
Index:
537 entries, European Union (EU6-1958, EU9-1973, EU10-1981, EU12-1986,
EU15-1995, EU25-2004, EU27-2007, EU28-2013) to Bosnia and Herzegovina
Data columns (total 58 columns):
1991 537 non-null object
Flags and footnotes 0 non-null float64
1992 537 non-null object
Flags and footnotes.1 0 non-null float64
1993 537 non-null object
Flags and footnotes.2 0 non-null float64
1994 537 non-null object
Flags and footnotes.3 0 non-null float64
1995 537 non-null object
Flags and footnotes.4 0 non-null float64
1996 537 non-null object
Flags and footnotes.5 0 non-null float64
1997 537 non-null object
Flags and footnotes.6 0 non-null float64
1998 537 non-null object
Flags and footnotes.7 0 non-null float64
1999 537 non-null object
Flags and footnotes.8 0 non-null float64
2000 537 non-null object
Flags and footnotes.9 0 non-null float64
2001 537 non-null object
Flags and footnotes.10 0 non-null float64
2002 537 non-null object
Flags and footnotes.11 0 non-null float64
2003 537 non-null object
Flags and footnotes.12 0 non-null float64
2004 537 non-null object
Flags and footnotes.13 0 non-null float64
2005 537 non-null object
Flags and footnotes.14 0 non-null float64
2006 537 non-null object
Flags and footnotes.15 0 non-null float64
2007 537 non-null object
Flags and footnotes.16 0 non-null float64
2008 537 non-null object
Flags and footnotes.17 1 non-null object
2009 537 non-null object
Flags and footnotes.18 26 non-null object
2010 537 non-null object
Flags and footnotes.19 6 non-null object
2011 537 non-null object
Flags and footnotes.20 6 non-null object
2012 537 non-null object
Flags and footnotes.21 14 non-null object
2013 537 non-null object
Flags and footnotes.22 33 non-null object
2014 537 non-null object
Flags and footnotes.23 44 non-null object
2015 537 non-null object
Flags and footnotes.24 12 non-null object
2016 537 non-null object
Flags and footnotes.25 16 non-null object
2017 537 non-null object
Flags and footnotes.26 16 non-null object
2018 537 non-null object
Flags and footnotes.27 41 non-null object
2019 537 non-null object
Flags and footnotes.28 0 non-null float64
dtypes: float64(18), object(40)
memory usage: 247.5+ KB
Estadísticas de las columnas
Otra manera básica de revisar los datos para identificar problemas es a través de un sumario estadístico que nos de una idea de lo que la tabla contiene.
Si el parámetro “include” es “all”, nos muestra todas las columnas.
Algunos valores serán “NaN” porque no tienen sentido para el tipo de dato de la columna.
Para datos numéricos include el número de elementos (count), la media (mean), la desviación estándar (str), el mínimo y máximo (min, max) y los percentiles 25, 50 y 75.
Para el resto de datos (texto y fechas), además del número de elementos (count), nos muestra el valor más común (top) y su frecuencia (freq).
Input [11]:
data.describe(include = "all")
Output [11]:
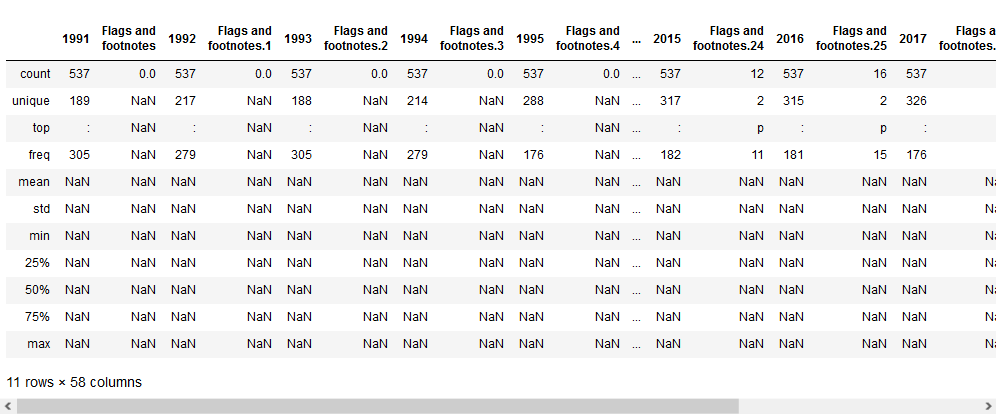
Las dos operaciones previas muestran una primera serie de problemas.
Por una parte, el tipo de datos de las columnas no es numérico. Esto implica que hay valores inválidos, tal y como se ve con la operación “describe”.
Además, hay una serie de “Flags” (banderas) que no contienen ninguna información. Estas son columnas descriptivas que pueden ser eliminadas.
Eliminar columnas innecesarias
Para eliminar columnas innecesarias se necesita saber sus nombres (o índices).
Input [12]:
print(data.columns)
Output [12]:
Index(['1991', 'Flags and footnotes', '1992', 'Flags and footnotes.1', '1993',
'Flags and footnotes.2', '1994', 'Flags and footnotes.3', '1995',
'Flags and footnotes.4', '1996', 'Flags and footnotes.5', '1997',
'Flags and footnotes.6', '1998', 'Flags and footnotes.7', '1999',
'Flags and footnotes.8', '2000', 'Flags and footnotes.9', '2001',
'Flags and footnotes.10', '2002', 'Flags and footnotes.11', '2003',
'Flags and footnotes.12', '2004', 'Flags and footnotes.13', '2005',
'Flags and footnotes.14', '2006', 'Flags and footnotes.15', '2007',
'Flags and footnotes.16', '2008', 'Flags and footnotes.17', '2009',
'Flags and footnotes.18', '2010', 'Flags and footnotes.19', '2011',
'Flags and footnotes.20', '2012', 'Flags and footnotes.21', '2013',
'Flags and footnotes.22', '2014', 'Flags and footnotes.23', '2015',
'Flags and footnotes.24', '2016', 'Flags and footnotes.25', '2017',
'Flags and footnotes.26', '2018', 'Flags and footnotes.27', '2019',
'Flags and footnotes.28'],
dtype='object')
Tienes que eliminar todas las columnas que empiezan con “Flags”.
Una primera manera de eliminarlas es una a una indicando su nombre.
Input [13]:
data = data.drop(columns=['Flags and footnotes'])
data.head(1)
Output [13]:

Pero también se pueden eliminar todas de golpe creando un vector con los nombres de las columnas que se van a borrar.
Esto se hace creando un vector con los nombres de las columnas que contienen “Flags” y después borrando todas las columnas de ese vector.
Input [14]:
indices = [i for i, s in enumerate(data.columns) if 'Flags' in s]
colToDelete=data.columns[np.array(indices)]
print(colToDelete)
Output [14]:
Index(['Flags and footnotes.1', 'Flags and footnotes.2',
'Flags and footnotes.3', 'Flags and footnotes.4',
'Flags and footnotes.5', 'Flags and footnotes.6',
'Flags and footnotes.7', 'Flags and footnotes.8',
'Flags and footnotes.9', 'Flags and footnotes.10',
'Flags and footnotes.11', 'Flags and footnotes.12',
'Flags and footnotes.13', 'Flags and footnotes.14',
'Flags and footnotes.15', 'Flags and footnotes.16',
'Flags and footnotes.17', 'Flags and footnotes.18',
'Flags and footnotes.19', 'Flags and footnotes.20',
'Flags and footnotes.21', 'Flags and footnotes.22',
'Flags and footnotes.23', 'Flags and footnotes.24',
'Flags and footnotes.25', 'Flags and footnotes.26',
'Flags and footnotes.27', 'Flags and footnotes.28'],
dtype='object')
Input [15]:
data = data.drop(columns=colToDelete)
data.head(1)
Output [15]:

Ajustar el nombre de las columnas o filas en la tabla
Podría ser necesario cambiar los nombres de los encabezados para hacerlos más relevantes.
Por ejemplo, puedes renombrar la primera columna, ya que contiene los nombres de las divisiones NUTS.
Input [17]:
data.index.names = ['NUTS']
También podemos ajustar los nombres de las filas si consideramos que pueden simplificar la lectura de la tabla.
Por ejemplo, podemos cambiar el nombre de la primera fila a “European Union”.
Input [18]:
data = data.rename(index={data.index.ravel()[0]: 'European Union'})
data.head()
Output [18]:

Limpieza de datos.
El análisis general podria darte una idea de que algo está mal, pero un análisis mas detallado de las columnas es necesario para identificar problemas en los valores.
Una buena estrategia de análisis es visualizar y/o contar el número de valores diferentes, ver el número de valores no numéricos o incluso ver si hay filas o columnas repetidas.
Contar valores diferentes en las columnas podría mostrar un problema en los datos.
· dataframe[column].count() muestra el número de valores en la columna.
· dataframe[column].unique() muestral el número de valores diferentes en la columna
· dataframe[column].value_counts() muestra el número de ocurrencia de cada valor
Podemos analizar la columna de 2019 mirando su contenido.
Input [19]:
print("Number of values", data['2019'].count())
print("Unique values", data['2019'].unique())
Output [19]:
Number of values 537
Unique values [':' 2373.1 0.72 1275.98 345.21 129.6 311.89 96.07 393.21 1096.4 45.33
279.47 241.17 311.55 218.87 1500 28 72 594 453 354]
Input [20]:
serie = data['2019'].value_counts()
serie
Output [20]:
: 517
28 1
279.47 1
129.6 1
2373.1 1
1096.4 1
393.21 1
72 1
594 1
311.55 1
345.21 1
1275.98 1
218.87 1
1500 1
96.07 1
354 1
453 1
45.33 1
241.17 1
311.89 1
0.72 1
Name: 2019, dtype: int64
Hay 537 valores en 2019 pero la mayoría de ellos son no-numéricos. Hay que cambiarlos a valores nulos.
Reemplazo de valores no numéricos.
Cambiabos todos los valores no numéricos a NaN (not a number) excepto la primera columna.
Se define una función para identificar si un valor es “float”.
Selecciona las columnas a filtrar y entonces añade la columna con los nombres.
Input [21]:
def isfloat(value):
try:
float(value)
return True
except ValueError:
return False
data= data.where(data.applymap(lambda x: isfloat(x)))
data.head(5)
Output [21]:
Continua… Módulo 3 – Capítulo 3