Capítulo 3 - Explicación

Previamente… Módulo 3 - Capítulo 2
Conversión del tipo de datos
Para poder hacer cualquier tipo de procesado, debes convertir las columnas a valores numéricos.
La conversion puede poner NaN a todos los valores no numéricos para que el paso anterior no sea necesario.
Input [22]:
data = data[data.columns].apply(pd.to_numeric, errors='coerce')
data.info()
Output [22]:
<class 'pandas.core.frame.DataFrame'>
Index: 537 entries, European Union to Bosnia and Herzegovina
Data columns (total 29 columns):
1991 232 non-null float64
1992 258 non-null float64
1993 232 non-null float64
1994 258 non-null float64
1995 361 non-null float64
1996 382 non-null float64
1997 355 non-null float64
1998 354 non-null float64
1999 384 non-null float64
2000 354 non-null float64
2001 396 non-null float64
2002 364 non-null float64
2003 402 non-null float64
2004 311 non-null float64
2005 151 non-null float64
2006 61 non-null float64
2007 328 non-null float64
2008 352 non-null float64
2009 347 non-null float64
2010 357 non-null float64
2011 352 non-null float64
2012 354 non-null float64
2013 355 non-null float64
2014 347 non-null float64
2015 355 non-null float64
2016 356 non-null float64
2017 361 non-null float64
2018 361 non-null float64
2019 20 non-null float64
dtypes: float64(29)
memory usage: 125.9+ KB
Input [23]:
data.describe(include = 'all')
Output [23]:

Estandarización de los contenidos.
Después de analizar los datos vemos que la columna NUTS tiene los nombres de los NUTS pero no los códigos.
El siguiente paso es estandarizar los contenidos de esa columna reemplazando las etiquetas con los códigos.
Para este propósito, tenemos un archivo que contiene las etiquetas.
Input [24]:
file = 'datos/nuts.xlsx'
nuts = pd.read_excel(file, index_col=0)
nuts.head(5)
Output [24]:

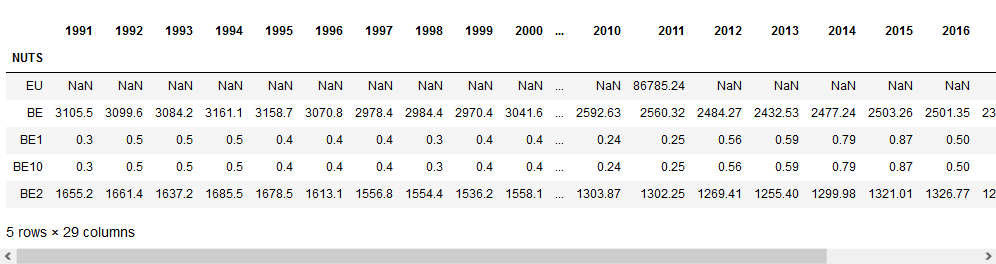
Ya que la información se organiza de manera similar, podemos cambiar un índice por otro.
Input [25]:
data.index = nuts.index
data.head(5)
Eliminando valores inválidos.
Dependiendo del problema puedes saber que los valores de las celdas deben estar entre un determinado rango. Por tanto, cualquier valor fuera de este rango no es válido y tiene que ser ajustado (min, max o NaN).
En el ejemplo discutido, los valores pueden ser solo positivos. Sin embargo, hay algunos valores negativos en la tabla.
· dataframe.lt() muestral el número de valores más bajos que los indicados
Input [26]:
data.lt(0).sum()
Output [26]:
1991 3
1992 3
1993 3
1994 3
1995 0
1996 0
1997 0
1998 0
1999 0
2000 0
2001 0
2002 0
2003 0
2004 0
2005 0
2006 0
2007 0
2008 0
2009 0
2010 0
2011 0
2012 0
2013 0
2014 0
2015 0
2016 0
2017 0
2018 0
2019 0
dtype: int64
Estos valores se pueden poner como 0 o cambiarlos a NaN
Input [27]:
data[data < 0] = np.nan
Visualización de datos nulos
Podemos ver cuantos de los 537 valores no numéricos tiene cada columna.
Dependiendo del problema a resolver puede ser necesario eliminar filas o columnas con NaN para tener datos completos.
· dataframe.isna() muestral los valores nulos del conjunto de datos
Input [28]:
data.isna().sum()
Output [28]:
1991 308
1992 282
1993 308
1994 282
1995 176
1996 155
1997 182
1998 183
1999 153
2000 183
2001 141
2002 173
2003 135
2004 226
2005 386
2006 476
2007 209
2008 185
2009 190
2010 180
2011 185
2012 183
2013 182
2014 190
2015 182
2016 181
2017 176
2018 176
2019 517
dtype: int64
Eliminar datos nulos
En caso de que necesitemos limpiar más datos y eliminar columnas que contengan algunos datos nulos, en este caso tendríamos que eliminar 2019, ya que los datos no están terminados. Así, tenemos que eliminar las columnas que no nos son útiles.
· dataframe.dropna() te permite eliminar columnas con datos nulos.
Input [29]:
data2 = data.dropna()
data2.describe()
Output [29]:

Se puede ver que en la colección de datos, hay columnas no completas.
Inteporlación de datos nulos.
Si los análisis a realizar no permiten hacer nulos los datos o eliminarlos ya que muchas filas se eliminarían, una alternativa es interpolar los valores.
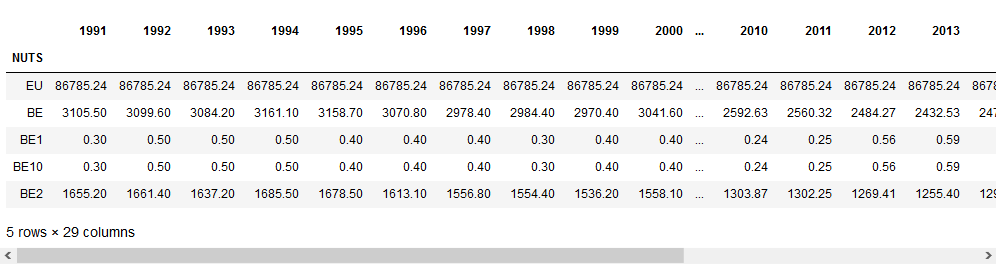
Input [30]:
data = data.interpolate(axis=1, limit_direction='both')
data.head()
Rellenar columnas vacias
La interpolación es imprecise con columnas con pocos datos, ya que apenas hay datos e información para deducir los valores que faltan. Un ejemplo es la primera fila de la tabla, donde solo hay 1 dato para la Unión Europea, por lo que la interpolación rellena todas las casillas con ese valor.
Otro problema son las filas completamente vacías. Aquí la interpolación no puede hacer nada. Una solución si necesitan tener valores es poner todas esas filas con valores 0.
dataframe.fillna() te permite cambiar un valor NaN a otro valor
Escribir archivos de datos
PARA APRENDER MÁS….
The formats supported in the Pandas library and how to write in them is described in: https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
Format | Read | Write |
csv | pd.read_csv() | pac.to_csv() |
json | pd.read_json() | pac.to_json() |
excel | pd.read_excel() | pac.to_excel() |
hdf | pd.read_hdf() | pac.to_hdf() |
sql | pd.read_sql() | pac.to_sql() |
... | ... | ... |
Cada operación de grabación en diferente formato necesita ajustar diferentes parametros.
Pandas nos permite guardar los datros en formato Excel con dataframe.to_excel().
Los parametros más relevantes son:
· io = The file location
· sheet_name = The sheet to be written
· index = If an index column should be put in the file
Input [32]:
data.to_excel('datos/animalEurostatNuts2_DataSheet_corrected.xlsx', sheet_name='Data')
El archivo usado como ejemplo contiene múltiples hojas que pueden ser procesadas de la misma manera ya que tienen la misma estructura.
Para automatizar el proceso, puedes leer todas las hojas y aplicar el proceso a cada una de ellas y guardar el resultado en un ahoja diferente del archivo de salida.
Primero, tenemos que definir una función que, dado un marco de datos, aplica el proceso de limpieza de datos entero.
Después, la función llama al proceso para cada hoja
Input [33]:
import pandas as pd
import numpy as np
nuts = pd.read_excel('datos/nuts.xlsx', index_col=0)
#function for Data cleaning
def cleanData(data):
#we eliminate leftover columns
indices = [i for i, s in enumerate(data.columns) if 'Flags' in s]
colToDelete=data.columns[np.array(indices)]
data = data.drop(columns=colToDelete)
#we change the header and first column
data.index = nuts.index
#we change data type and remove no numbers
data = data[data.columns].apply(pd.to_numeric, errors='coerce')
#we eliminate duplicate rows
data = data.loc[~data.index.duplicated(keep='first')]
#we delete negative values
data[data < 0] = np.nan
#we interpolate null values
data = data.interpolate(axis=1, limit_direction='both')
#we add zeros to the empty rows
data = data.fillna(0)
return data
Input [34]:
reader = pd.ExcelFile('datos/animalEurostatNuts2.xlsx')
writer = pd.ExcelWriter('datos/animalEurostatNuts2_corrected.xlsx')
for sheet in reader.sheet_names:
data = pd.read_excel(reader, sheet_name=sheet, skiprows=9, skipfooter=13, index_col=0)
data = cleanData(data)
data.to_excel(writer, sheet_name=sheet)
writer.save()
print('Done')
Output [34]:
Done
Continua… Módulo 3 – Capítulo 4