
Capítulo 4 - Explicación

Este tema describirá los procesos usados para analizar el contenido de los datos.
Repaso de los datos a procesar
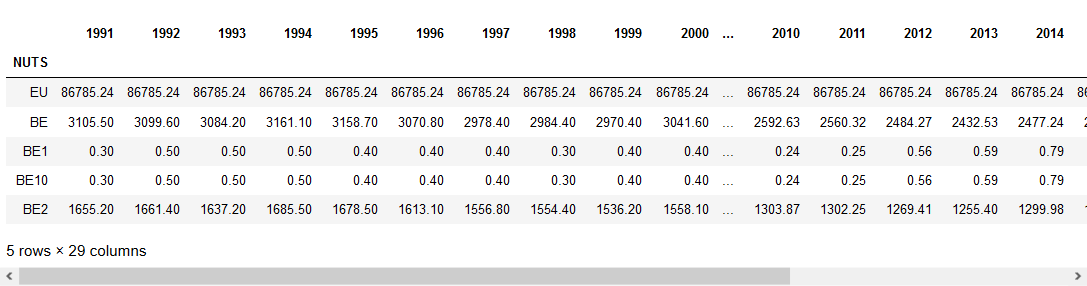
Vamos a practicar el análisis de datos en una Jupyter Notebook con las librerías Pandas de un archivo Excel con información sobre producción de ganado en Europa que ha sido limpiada en el tema anterior
Input [1]:
import pandas as pd
import numpy as np
file = 'datos/animalEurostatNuts2_corrected.xlsx'
data = pd.read_excel(file, sheet_name='Data', index_col=0)
data.head(5)
Identificación de correlaciones
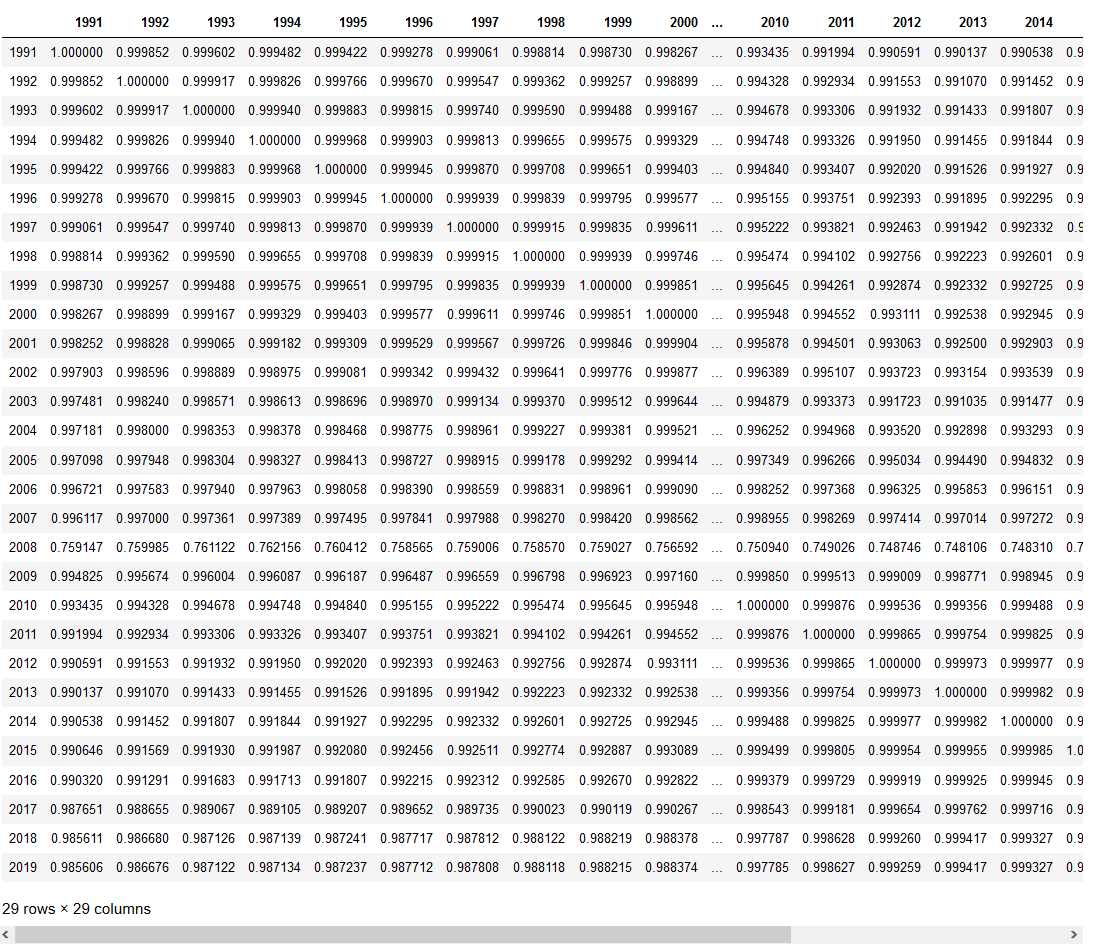
Identificar correspondencias entre conjuntos de datos numéricos es importante para determinar si hay columnas con información redundante (o para detectar dos columnas que deberían estar correlacionadas y no lo están)
· dataframe.corr() muestral la correlación entre las columnas del conjunto de datos.
Input [2]:
data.corr()
Output [2]:
Las correlaciones se pueden ver en un mapa de color. Ya que es complejo, definamos la función “heatmap” para reutilizarla.
Input [3]:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(rc={'figure.figsize'12,6)})
pal=sns.diverging_palette(220, 20, n=100)
def heatmap(c):
ax = sns.heatmap(c, vmin=-1, vmax=1, center=0, cmap=pal,square=True)
ax.set_xticklabels(ax.get_xticklabels(), rotation=45,horizontalalignment='right');
sns.palplot(pal)
Output [3]:
![]()
Input [4]:
%matplotlib inline
corr = data.corr()
heatmap(corr)
Output [4]:
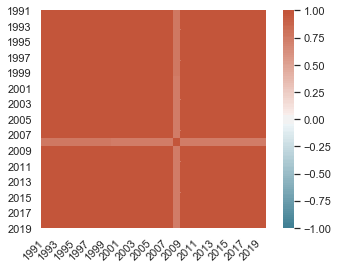
Puedes ver que los datos están altamente correlacionados anualmente
Los reorganizaremos para ver la correlación entre regiones transponiendo los datos.
· dataframe.T transpone un conjunto de datos
Input [5]:
dataT = data.T
dataT.head()
Output [5]:

Input [6]:
corr = dataT.corr()
heatmap(corr)
Output [6]:
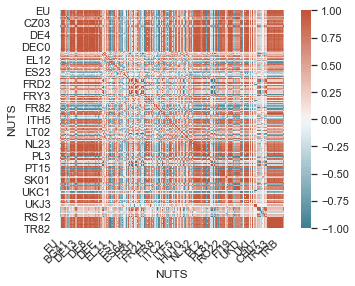
Se puede ver que en el caso de la producción anual entre regiones esta no está tan correlacionada, hay grupos de regiones que se comportan de forma similar pero otras no.
Para interpretar mejor los datos obtendremos una muestral de los datos centrada en España.
· dataframe.iloc te permite elegir un rango de filas y columnas como un nuevo conjunto de datos.
Input [7]:
dataTSub = dataT.loc[:,'ES':'ES70']
dataTSub.head()
Output [7]:
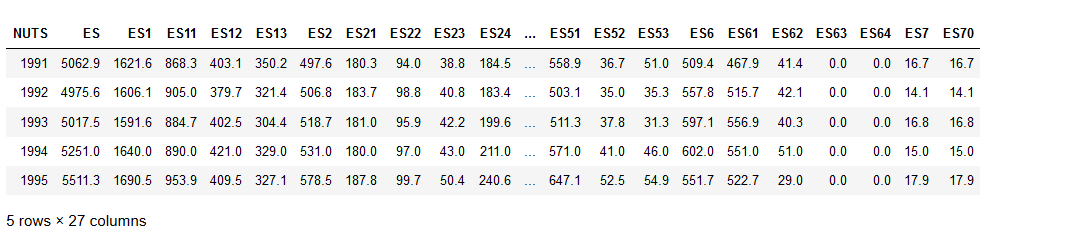
Input [8]:
corr = dataTSub.corr()
heatmap(corr)
Output [8]:

Si estamos interesados en saber si los datos observados son consistentes con una correlación debemos calcular el p-value.
Si el p-value está entre 0.0 y 0.05 se considera que hay correlación estadística evidente.
· stats.pearsonr permite obtener el coeficiente de pearson y el p-value entre dos series de datos.
Input [9]:
from scipy import stats
# Aragón (ES24) vs Cataluña (ES51)
pearson_coef, p_value = stats.pearsonr(dataTSub['ES24'], dataTSub['ES51'])
print("Pearson's correlation coefficient is {0:.8f} with a p-value of {1:.8f}".format(pearson_coef, p_value))
# Noreste (ES1) vs Galicia (ES11)
pearson_coef, p_value = stats.pearsonr(dataTSub['ES1'], dataTSub['ES11'])
print("Pearson's correlation coefficient is {0:.8f} with a p-value of {1:.8f}".format(pearson_coef, p_value))
Output [9]:
Pearson's correlation coefficient is 0.31009222 with a p-value of 0.10161273
Pearson's correlation coefficient is 0.86482739 with a p-value of 0.00000000
Visualización de las series de datos.
Una visión gráfica de los datos puede ayudarnos a entenderlos mejor.
dataframe.plot permite una amplia variedad de visualizaciones de diferentes tipos de datos.
Input [10]
dataTSub.plot(kind='line', figsize =(20,10))
<matplotlib.axes._subplots.AxesSubplot at 0x26715d9f608>
Output [10]:
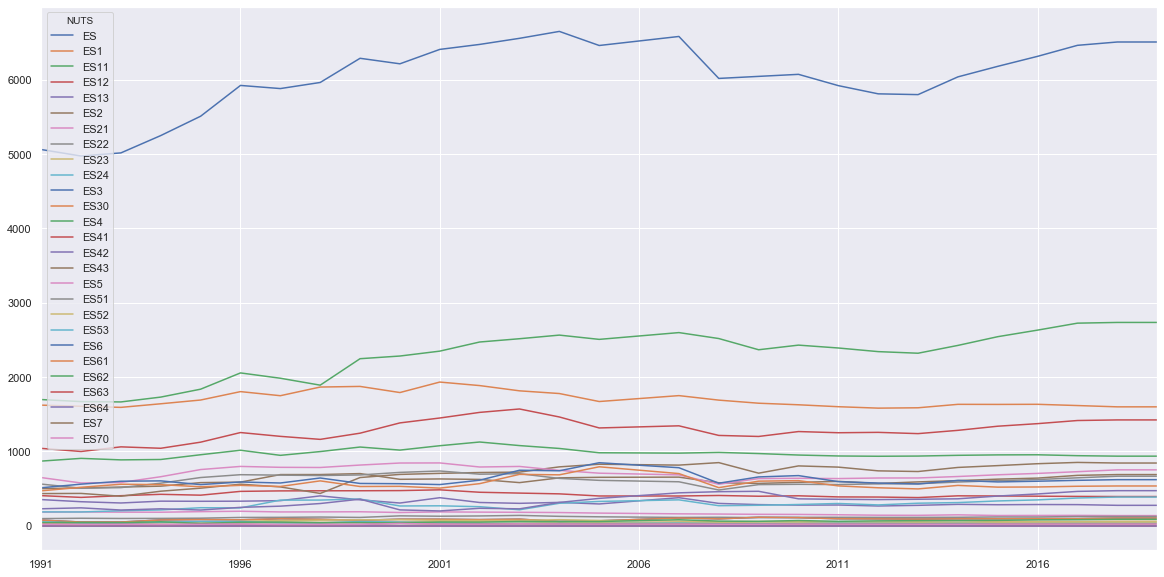
También puedes visualizar la correlación entre series usando un gráfico de relación linear.
· regplot() de la librería SeaBorn te permite mostra el grado de relación linear entre series
Input [11]:
sns.regplot(x="ES1", y="ES11", data=dataTSub)
<matplotlib.axes._subplots.AxesSubplot at 0x26716a0b388>
Output [11]:

Input [12]:
sns.regplot(x="1991", y="2018", data=data)
<matplotlib.axes._subplots.AxesSubplot at 0x26715b7c908>
Output [12]:
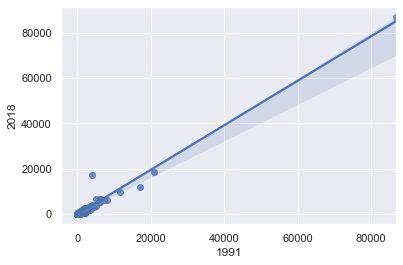
Si los datos a analizar son rangos, hay visualizaciones más informativas.
Es mejor usar un boxplot que muestra la dispersión de los valores respecto a las categorías.

El “boxplot” es una herramienta muy útil para identificar como una serie de datos se desvía de la media e incluso para ver si hay posibles datos espurios (muy alejados de la media).
· dataframe.boxplot te permite visualizar el boxplot de las columnas deseadas en la tabla.
Input [13]:
import matplotlib.pyplot as plt
dataTSub[dataTSub.columns[1:5]].boxplot()
<matplotlib.axes._subplots.AxesSubplot at 0x267167e8908>
Output [13]:

Continua… Módulo 3 – Capítulo 5